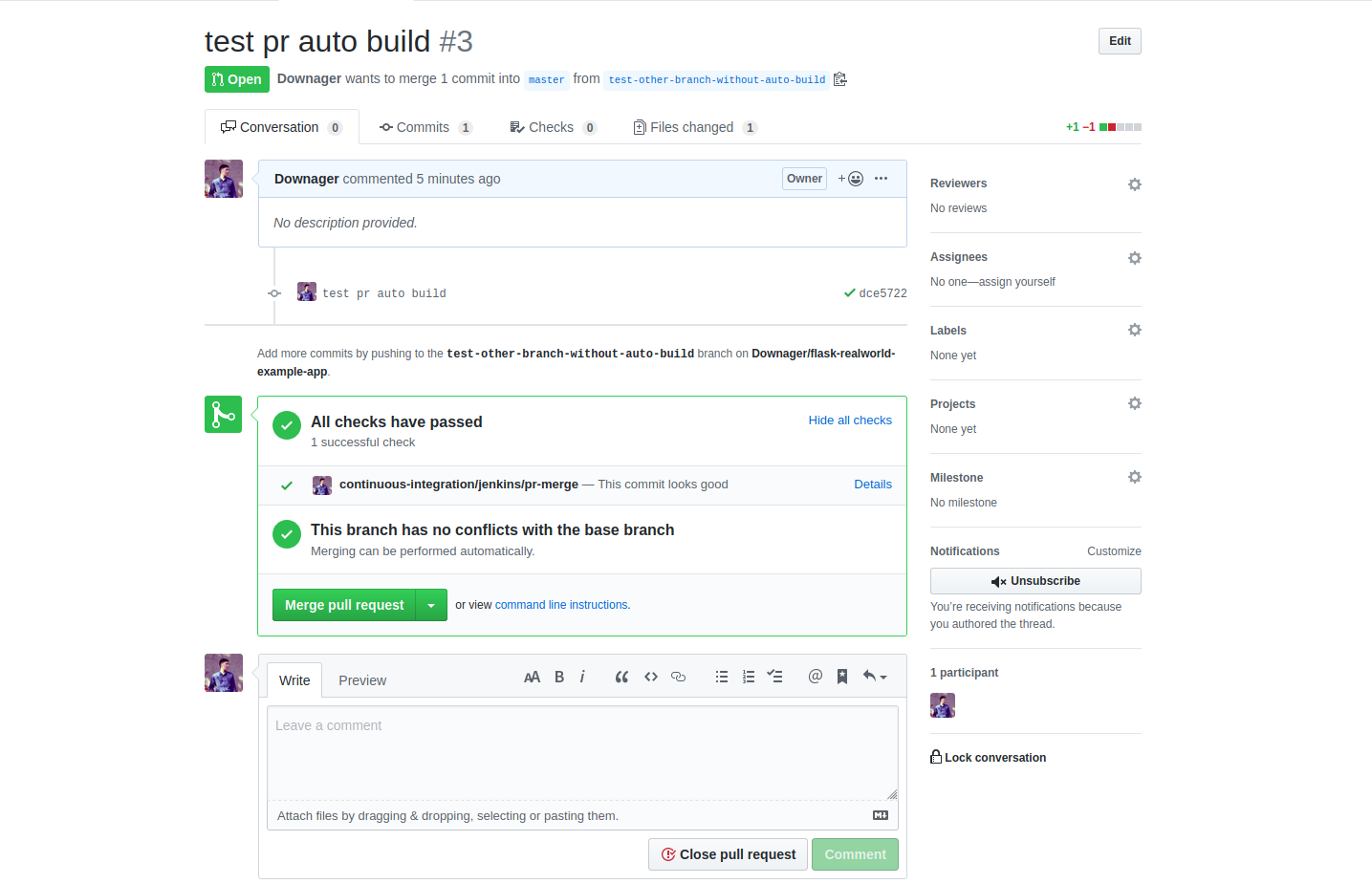
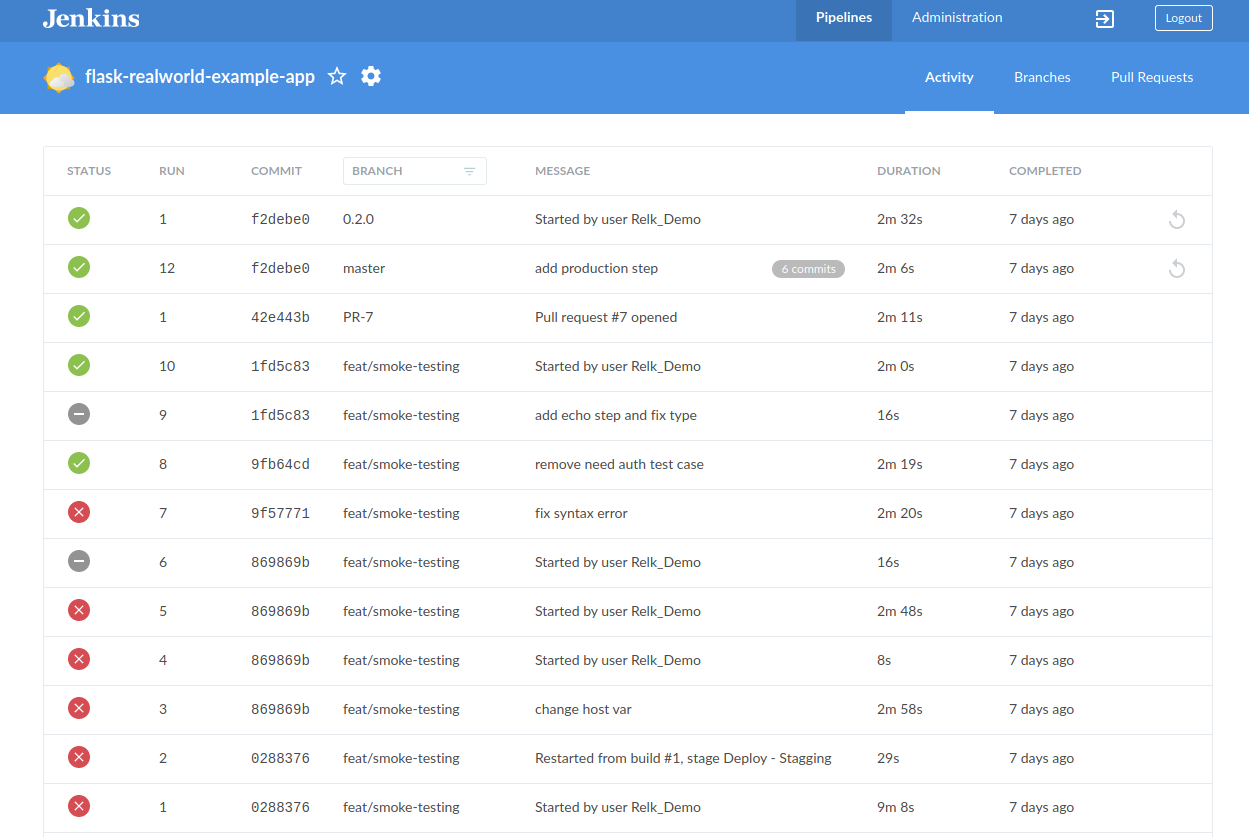
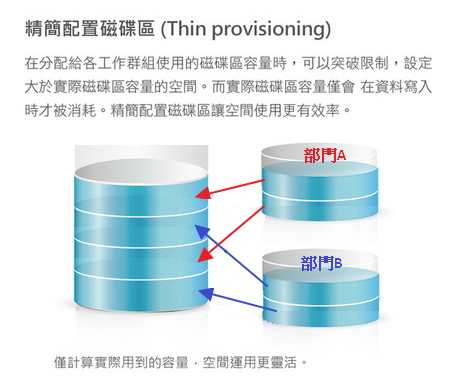
GKE 上原生的 Ingress Controller 限制非常多,需要設定 ServiceType=NodePort 才能使用,
於是我選擇 kubernetes/ingress-nginx 來作為 ingress 使用,不要和我一樣一開始裝成 nginxinc/kubernetes-ingress 的 Ingress Controller XD
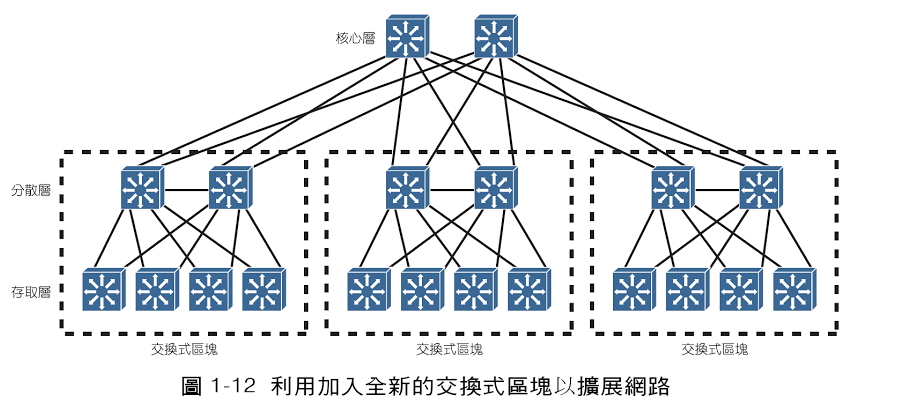
這張圖是 Kube Ingress Controller 在 GKE 上的架構,除了 external 以外我還需要 internal 的 ingress

所以我總共會起兩個 Ingress Controller,Ingress Class 分別是 nginx 與 nginx-internal,
只要在 Ingress Controller 的 Service annotations 加上 cloud.google.com/load-balancer-type: "Internal",
GKE 就會起 Internal Loadbalancer 給你的 ingress controller,詳細可以參考以下步驟來安裝
安裝步驟
- 下載 kube-ingress 的 helm chart
1
2
3
4helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
helm repo update
helm fetch ingress-nginx/ingress-nginx
tar zxvf ingress-nginx-2.1.0.tgz - 安裝 external kube-ingress,根據自己需求修改 default value
1
helm upgrade --install ingress-nginx --namespace default ingress-nginx/
- 新建一個叫
internal-values.yml的文件,放到ingress-nginx/底下1
2
3
4
5controller:
ingressClass: nginx-internal
service:
annotations:
cloud.google.com/load-balancer-type: "Internal" - 安裝 internal kube-ingress
1
helm upgrade --install ingress-nginx-internal --namespace default ingress-nginx/ -f internal-values.yml
- 檢查 ingress controller 的 LoadBalancer 是否如預期配到需要的 IP
1
2
3
4
5# relk @ relk-Inspiron-7375 in ~ [0:35:09]
$ k get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller LoadBalancer 10.202.0.24 35.***.***.164 80:30499/TCP,443:31137/TCP 32h
ingress-nginx-internal-controller LoadBalancer 10.202.15.138 10.200.***.*** 80:32401/TCP,443:32427/TCP 32h
測試
- 宣告新的 ingress,在 annotations 下指定你要哪種 ingress class (Repo: gke-kube-ingress-demo)
1
2
3
4# External Ingress
kubernetes.io/ingress.class: nginx
# Internal Ingress
kubernetes.io/ingress.class: nginx-internal - 檢查結果
1
2
3
4
5# relk @ relk-Inspiron-7375 in ~ [0:59:35]
$ kgi
NAME HOSTS ADDRESS PORTS AGE
demo-app demo-app.example.com 35.***.***.164 80 35s
demo-app-internal demo-app-internal.example.com 10.200.***.*** 80 29s


 ]]>
]]>